
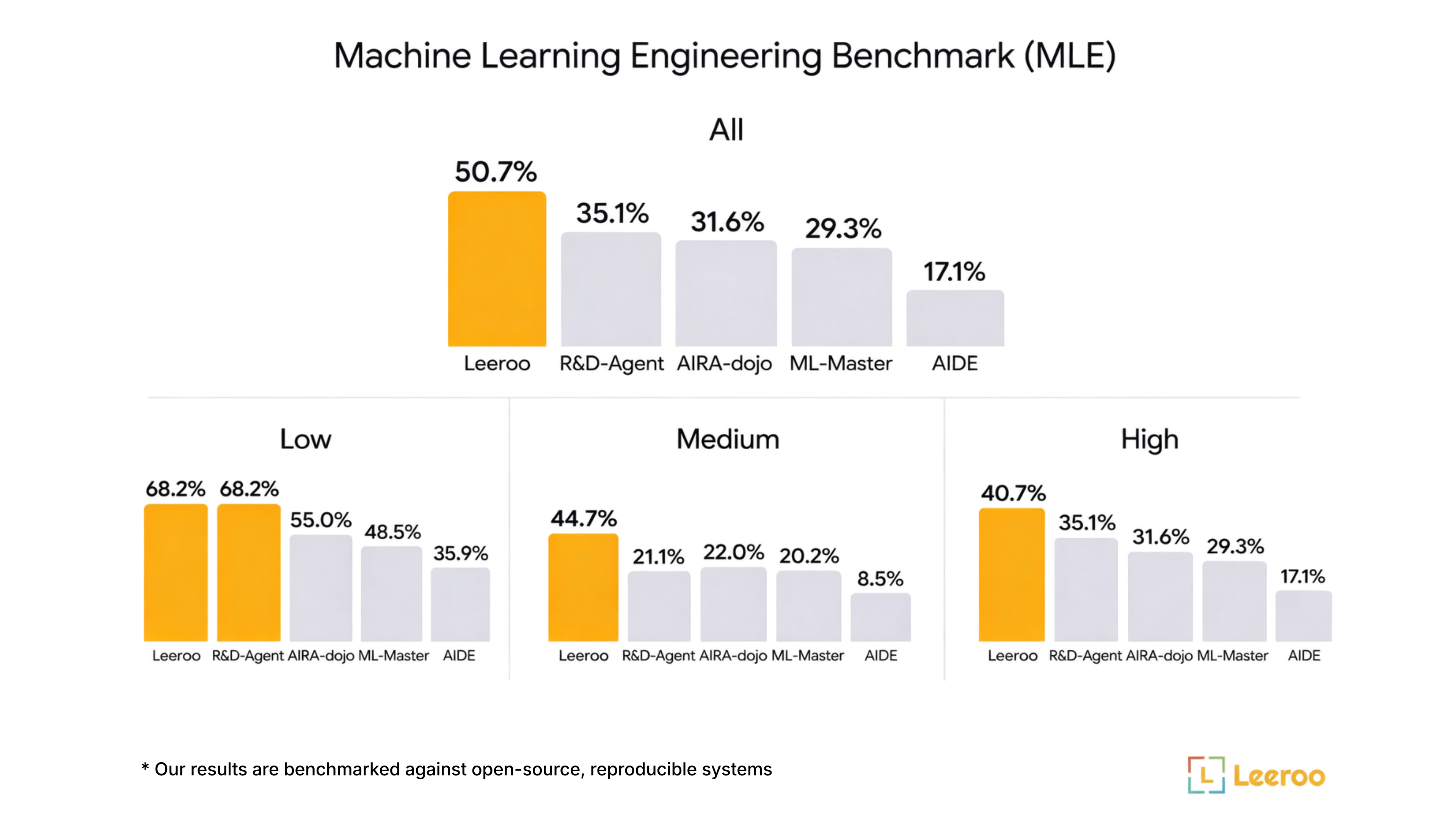
These results were submitted as an official submission to MLE-Bench.
Usage
CLI Options
Configuration Modes
MLE-Bench uses
benchmark_tree_search strategy which uses the handler’s built-in evaluation via handler.run(). This is different from kapso.evolve() which uses agent-built evaluation.- MLE_CONFIGS
- MINIMAL
Production configuration with full features.
Stages
The handler automatically adjusts strategy based on budget progress:Output Structure
The agent generates:Code Requirements
Generated code must:- Support
--debugflag for fast testing - Write
final_submission.csvin the output directory - Print progress and metrics
- Handle GPU efficiently (batch size, device selection)
- Use early stopping and learning rate scheduling